

Introduction
The rapid evolution of artificial intelligence (AI) has introduced new opportunities in engineering verification and quality control. One of the most complex challenges in this field is the automatic comparison of two versions of an engineering drawing, a task that requires visual recognition of all components in the drawing and an understanding of their engineering significance.
This research examined how effectively a conversational Large Language Model (LLM) can identify engineering relevant changes between different versions of technical drawings, while evaluating the nature and efficiency of its workflow. Specifically, this study focused on OpenAI’s GPT-5 model.
More than twenty separate comparisons were conducted. In each case, the LLM received clear instructions to detect only changes of true engineering significance - those that affect the form, fit, or function (FFF) of the design, such as modifications in dimensions, tolerances, geometry, or tabular data. Changes that do not influence these aspects - such as alterations in color, layout, text placement, or other graphical details - were considered non-engineering modifications and were therefore excluded from the analysis.
The primary goal was to evaluate the model’s ability to operate autonomously, accurately recognize changes with genuine engineering relevance, and produce a reliable report - while also testing how efficient and intuitive the interaction process truly is, without constant human intervention.
Methodology
The experiment began with a precise and structured prompt. The LLM was provided with two PDF engineering drawings containing various annotations - textual and symbolic elements such as dimensions, tolerances, notes, and tabular data that convey essential design information.
The model was instructed to analyze these annotations and generate a detailed report classifying each detected difference as added, deleted, or modified between the two versions. The prompt emphasized accuracy, clarity, and engineering relevance, directing the model to focus solely on technical changes rather than visual or stylistic variations.
More than twenty test cases were conducted, each consisting of two sequential drawing revisions in PDF format. The model received identical instructions for every case and was required to perform the analysis autonomously.
Each generated report was compared with a manually verified reference to evaluate accuracy and consistency, using three key metrics:
- Detection Precision - proportion of correctly identified engineering changes.
- Completeness - ability to detect all relevant modifications without missing significant ones.
- Interaction Efficiency - level of independence shown by the model, measured by how little human clarification or repetition was needed.
Using identical prompts across all cases ensured a fair and consistent evaluation of the model’s capability to detect engineering-relevant changes between drawing revisions.
Findings
Across more than twenty test cases, consistent patterns of strengths and limitations emerged.
The following table presents the summarized results obtained across all comparisons conducted during the study.
Table 1: Summary of Results Across All Test Cases
As shown in Table 1, the model detected only a portion of the actual engineering changes and additionally produced a high number of false positive detections.
The most critical issue was the occurrence of false negatives (FNs) - cases where the model missed actual engineering changes, directly compromising design integrity.
The model was able to describe differences but not to fully understand their geometric or contextual implications, frequently misclassifying tolerance edits, misinterpreting tabular data, and at times inventing details that did not exist in the drawings.
While it could reliably detect obvious and visually prominent changes, it often failed to capture subtle yet engineering-significant modifications.
The following figures present a visual summary of the model’s performance across all test cases.
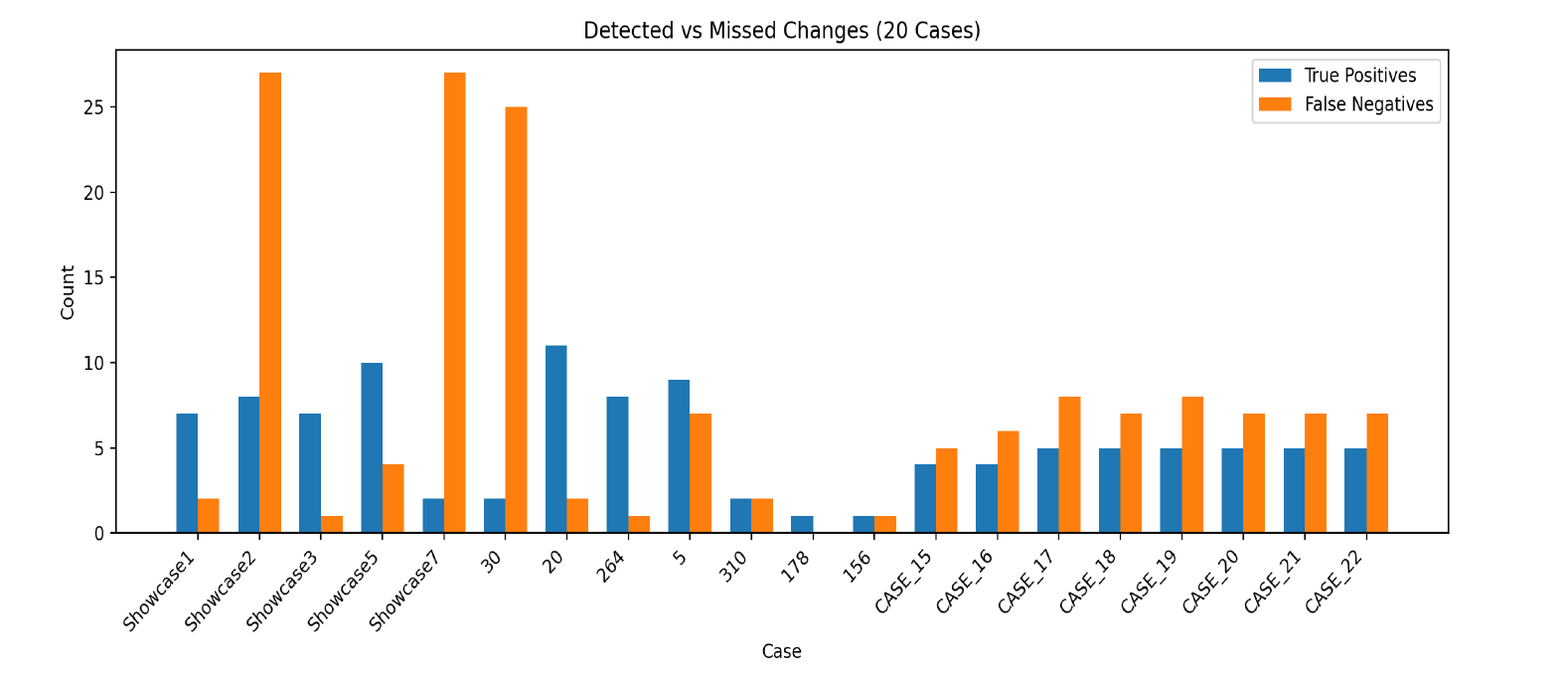
Figure 1: Detected vs Missed Changes per case (TP vs FN).
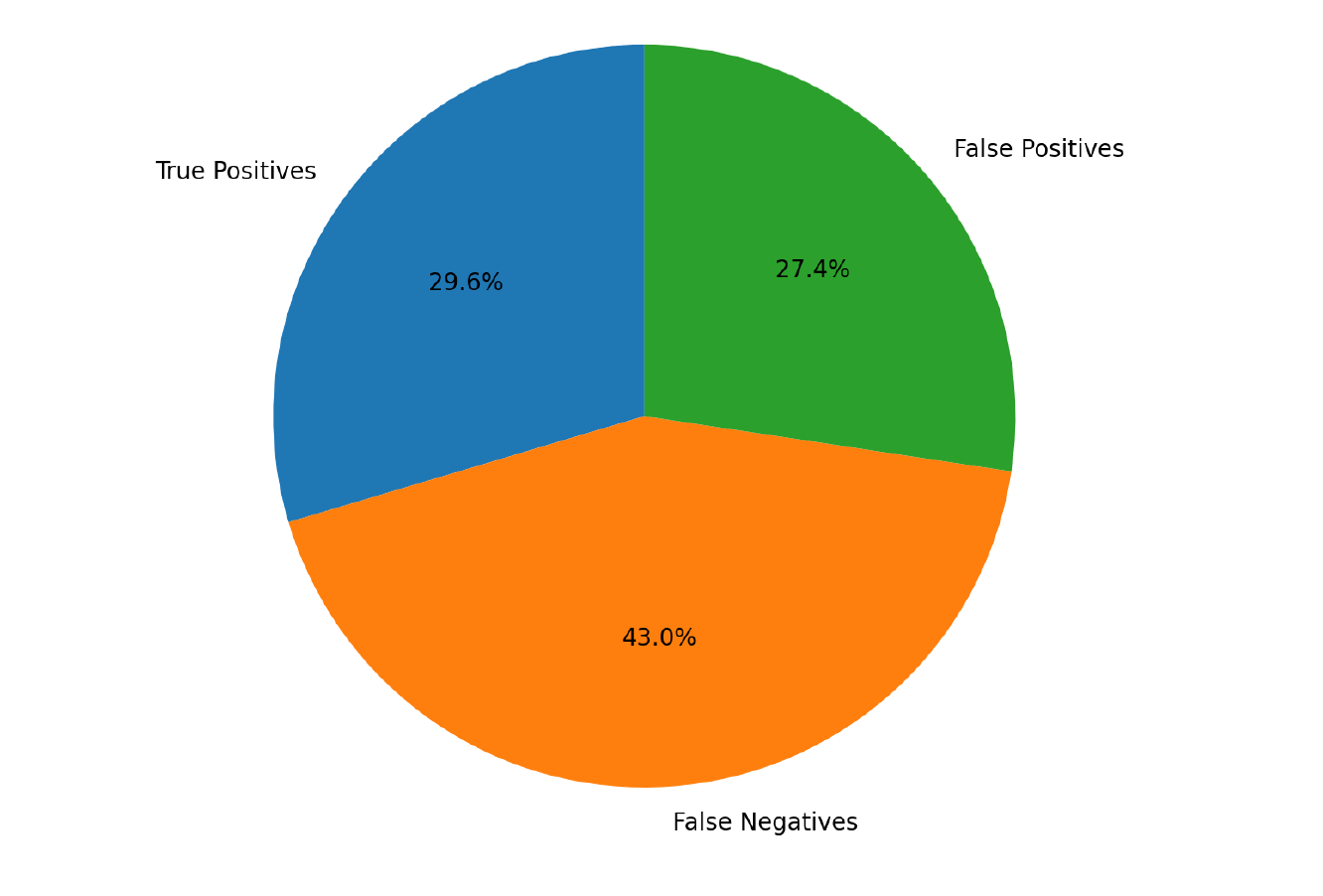
Figure 2: Overall detection breakdown (TP, FN, FP).
An examination of Figures 1 and 2 reveals that the rate of False Negatives is particularly high, indicating that the model’s main limitation is not minor or incidental, but rather substantial and directly affecting the reliability of the comparison results.
In addition, a significant number of False Positives was observed, reflecting numerous unnecessary detections that hinder efficient analysis and require human intervention for filtering and correction.
The interaction with the AI became a research focus in itself. The model required continuous human involvement, repeatedly asking for confirmation before proceeding, pausing mid-process for clarification, and frequently demanding manual intervention to continue. Instead of a smooth and autonomous workflow, the process became slow, cumbersome, and often frustrating, with meaningful progress achieved only after repeated corrections and detailed guidance. The model often displayed status messages indicating that it was “working on the task” for extended periods yet produced little to no meaningful output.
This dependency on human oversight revealed the system’s fundamental limitation - it still cannot perform a genuine engineering comparison without supervision.
Toward the end of the study, a decrease in false positives was observed; however, this did not reflect an actual improvement in analytical capability, but rather resulted from the later drawings containing fewer real modifications. False negatives persisted across all test cases, marking the model’s most consistent and unresolved limitation.
Discussion
The findings reveal a clear gap between the model’s ability to interpret text and its understanding of engineering and design information.
While the LLM detected explicit textual differences, it often missed subtle geometric or contextual changes due to its reliance on textual rather than spatial reasoning.
The high rate of False Negatives indicates that the model does not fully comprehend engineering intent, while the large number of False Positives demonstrates an oversensitivity to non-technical variations, reducing both accuracy and efficiency in the comparison process.
Moreover, in many cases, the model invented changes and annotations that did not exist in the drawings, reflecting a lack of consistency and a tendency to generate fabricated or hallucinatory details - a behavior that can be misleading in engineering verification workflows.
Throughout the study, constant human supervision was required, as the model frequently sought clarification and guidance. This dependency underscores that the model is far from being autonomous and unsuitable for professional engineering environments without expert oversight.
In summary, although large language models demonstrate some potential in assisting with documentation and textual comparison tasks, they remain far from achieving reliable spatial and geometric reasoning necessary for independent engineering drawing verification, and they often generate false or imagined data that undermines the credibility of their results.
Conclusion
After twenty independent experiments, it can be concluded that a conversational Large Language Model (LLM) alone cannot provide a complete or reliable analysis of engineering drawings.
Its strengths lie in data organization and structured reporting, yet its weaknesses - dependence on human supervision, limited engineering comprehension, and recurring false negatives - make it unreliable for independent verification tasks.
To achieve a truly autonomous and dependable system, the LLM must be integrated with advanced algorithms, computer vision, and data analysis mechanisms that enable a broader understanding of design intent and geometric context. For a deeper exploration of what such an integrated solution can look like in practice, check this article.
However, when operating under the guidance of a human engineer, the LLM can effectively assist in documenting and summarizing detected changes.
For now, the ultimate responsibility for engineering accuracy and interpretation remains clearly in human hands. A platform like bananaz, which integrates AI computer vision with advanced engineering-focused algorithms can significantly reduce the repetitive and time-consuming tasks mechanical engineers face in their daily workflows.

.png)


