

This article was brought to you by bananaz. At bananaz, we believe AI should support and elevate engineering decision-making, not replace it. As this study demonstrates, large language models can provide valuable secondary insight, but real trust in AI for mechanical engineers is achieved only when these models are embedded within systems that understand geometry, manufacturability, design intent, and design change history. By combining LLM reasoning with computer vision and advanced engineering algorithms, bananaz transforms AI from an isolated assistant into a reliable Copilot for mechanical engineers, helping teams move faster while reducing risk.
For the results only: click here
All models were evaluated as advisory tools only, not as decision-makers.
Abstract
The integration of AI for mechanical engineering is gaining momentum as Large Language Models (LLMs) are increasingly proposed as assistants in technical workflows; yet, empirical evidence regarding their performance is limited. This study compares the four LLMs - ChatGPT, Gemini, Claude, and Grok - using a controlled set of identical prompts covering theoretical engineering knowledge, interpretation of technical drawings, and Design for Manufacturing (DFM) analysis of 3D models. Their responses were evaluated for technical accuracy, reasoning depth, geometric interpretation, and usability. Results show substantial variation among the models: Gemini demonstrated the strongest and most consistent mechanical engineering reasoning, ChatGPT was capable but less stable, Claude was intelligent but overly concise, and Grok was the least reliable. LLMs can meaningfully support engineering workflows, but currently serve best as secondary reviewers rather than replacements for human engineers.
Model Versions:
- Gemini 3 Pro
- ChatGPT 5.1 Pro
- Claude Opus 4.5
- Grok 4.1
All models were accessed through their official user interfaces. No fine-tuning, system-level customization, or external tools were applied.
Introduction
As artificial intelligence becomes integrated into nearly every layer of modern industry, mechanical engineers face a new and practical question - not whether AI should be used, but which AI tools can be trusted. This raises deeper concerns: Can a language model meaningfully replicate the expert judgment required to interpret engineering drawings? Can it independently detect design flaws or manufacturability issues in complex 3D models?
Despite rapid technological progress, structured evidence assessing the real-world viability of AI for mechanical engineering remains scarce. To address this gap, a comparative evaluation of four leading models - ChatGPT, Gemini, Claude, and Grok - was conducted. Each model was tested using its most advanced available version, ensuring that the comparison reflects their highest current capabilities. Each model received the exact same prompts, enabling a consistent and fair comparison. The purpose was not to declare a universal “winner,” but to understand how each model reasons, how it assists the engineering thought process, and where its limitations introduce risk.
Methodology
The evaluation consisted of three main types of tasks:
- Theoretical engineering questions – including minimum edge distance in aluminum castings, minimum bend radius for stainless steel (ASTM), hydrogen embrittlement risks in zinc plated bolts, and thread engagement calculations.
- Interpretation of engineering drawings – such as selecting alternatives to PEM inserts in thin sheet metal, evaluating datum definitions, assessing GD&T correctness, and reviewing the logic and stability of dimensioning schemes.
- Analysis of 3D models – including manufacturability (DFM), CNC tool access, wall thickness constraints, minimum feature spacing, symmetry considerations, and general geometric feasibility.
All four models responses were evaluated not only for correctness, but also for:
- Depth and clarity of technical explanation.
- Ability to extract relevant geometric information from drawings and models.
- Caution when data was incomplete or ambiguous.
- Usability: readability, context retention, and consistency.
Although qualitative in nature, the structured testing yielded clear and consistent behavioral patterns.

Results
Theoretical Engineering Knowledge
All four models produced generally correct answers. However, their reasoning styles differed:
- Gemini: delivered the clearest, most intuitive explanations, often validating assumptions and providing engineering contextual reasoning.
- ChatGPT: performed well but required more guidance and sometimes offered broader, less focused answers.
- Claude: displayed strong numerical reasoning but tended to be overly concise, occasionally omitting essential context.
- Grok: relied heavily on standards without deeper engineering interpretation.
Gemini and Claude most closely resembled the reasoning of an engineer, with Gemini offering stronger clarity.
Engineering Drawing Interpretation
The drawing based tasks revealed greater variation.
- Gemini performed exceptionally, correctly identifying material, thickness, fastening logic, GD&T issues, and providing actionable corrections.
- ChatGPT understood key concepts but often required explicit prompting, especially when geometric inference was needed.
- Claude demonstrated partial understanding but missed critical issues or validated flawed drawings.
- Grok frequently lost context, misinterpreted drawings, or answered based on a previous prompt.
Gemini was the only model to consistently combine correct interpretation with practical engineering guidance.
3D Model Analysis (DFM & CNC)
Gemini was the strongest performer by a significant margin.
Across both 3D models (machined L bracket and bent sheet metal bracket):
- Gemini:
- Identified all major manufacturability issues
- Explained implications clearly (tool access, deflection, fixturing, cycle time)
- Proposed specific and realistic improvements
- Correctly determined when spacing or geometry violated manufacturing rules
- Provided reasoning resembling that of an experienced mechanical engineer
- ChatGPT: recognized many of the same issues but in shorter, less detailed explanations.
- Claude: identified some issues but was inconsistent and too brief.
- Grok: misinterpreted geometry, invented issues, or incorrectly approved invalid designs.
Gemini was the only model to deliver complete, correct, and actionable engineering reasoning.
Usability and Workflow Behavior
Usability varied significantly:
- Gemini: most readable, most consistent, minimal prompting required
- ChatGPT: strong but occasionally lost context or required clarification
- Claude: readable but short and required guidance
- Grok: frequently lost workflow coherence and context
Summary of AI Model Performance Across Evaluation Domains
The table illustrates clear performance differences. Gemini stands out across all categories, especially in drawing interpretation and 3D manufacturability analysis. ChatGPT performs well but less consistently. Claude shows capability but lacks reliability. Grok is not yet suitable for precision engineering tasks.
Discussion
The study highlights substantial differences between LLMs in their suitability for AI for mechanical engineering. Gemini consistently produced reasoning closest to that of a human engineer. ChatGPT, though strong, required intervention. Claude was insightful but too concise for critical engineering evaluations. Grok struggled significantly.
All models made mistakes; none can serve as an authoritative engineering decision maker. Their value lies in augmenting engineers - not replacing them.
Conclusions
Among the tested models:
- Gemini demonstrated the strongest, most consistent engineering reasoning
- ChatGPT was robust but uneven
- Claude showed potential but lacked reliability
- Grok was not suitable for engineering critical tasks
Even the strongest standalone LLM demonstrated limitations that make blind reliance risky in real engineering workflows. Relying on general-purpose LLMs alone is rarely sufficient for high-stakes mechanical engineering work. To achieve trustworthy, production-grade results, these models must be embedded within platforms that combine them with computer vision, structured engineering logic, and domain-specific validation pipelines.
Solutions like bananaz go beyond standalone AI reasoning by embedding LLMs into a design-aware engineering platform that understands CAD geometry, design changes, and manufacturing constraints. By grounding AI insights in real design data, structured rules, and continuous change tracking, bananaz turns LLM output into a verifiable, auditable, and production-ready engineering workflow, enabling teams to move faster without compromising design integrity or manufacturability.
Appendix A – Evaluation Prompts and Test Artifacts
This appendix presents the evaluation prompts used in the study, together with the engineering drawings and 3D models on which selected prompts were applied. All models were tested using identical inputs and identical supporting materials.
A.1 Theoretical Engineering Questions
The following questions were used to evaluate fundamental mechanical engineering knowledge, familiarity with standards, and the quality of engineering reasoning.
- In an aluminum casting made of 6061-T6 with a wall thickness of 5 mm, where a 3 mm diameter hole is drilled after casting, what is the recommended minimum distance between the hole and the edge of the part to prevent cracking or distortion according to common manufacturing guidelines?
- For spring stainless steel AISI 301 with a thickness of 0.8 mm, what is the minimum recommended bend radius according to ASTM A666 to prevent cracking during a 180° bend?
- How can thread stripping failure be evaluated, and how is the minimum required thread engagement depth determined, considering the bolt strength grade according to ISO 898-1?
- Is zinc plating according to ASTM B633 or ISO 4042 suitable for high-strength steel bolts? What is the associated risk of hydrogen embrittlement?
A.2 Engineering Drawing Interpretation Questions
These questions assessed the models’ ability to interpret geometric intent, GD&T, and manufacturability considerations based on 2D engineering drawings.
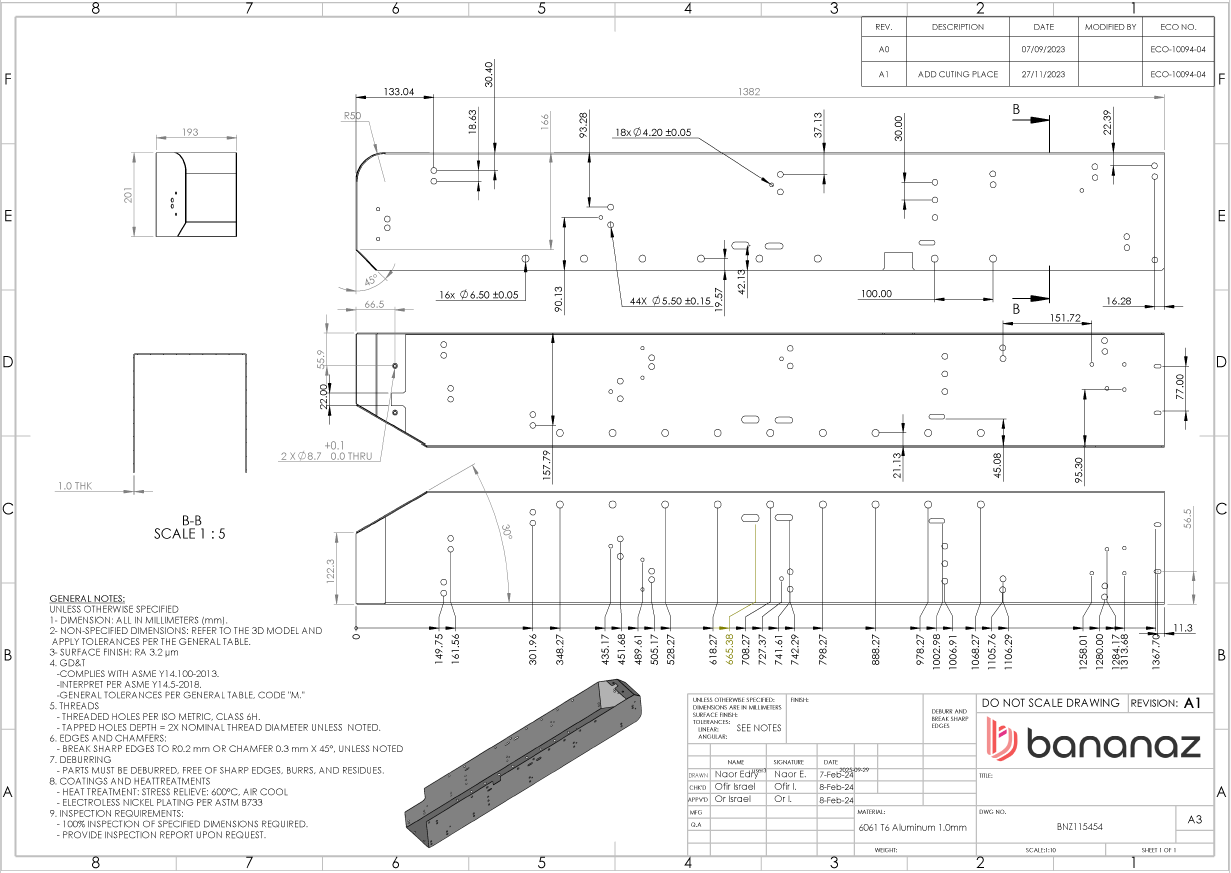
Description:
Sheet-metal component with a nominal thickness of 1 mm, including multiple holes defined as preparation holes for self-clinching fasteners.
- The holes Ø4.20, Ø5.50, and Ø6.50 are defined as PEM preparation holes in a 1 mm thick sheet metal part. What are suitable alternatives to self clinching inserts for M3, M4, and M5 threads, considering strength and manufacturability?
Description:
Machined component featuring multiple functional holes and planar surfaces, with datum definitions and GD&T callouts used to establish referencing, positional accuracy, and overall design intent clarity.
- Based on the drawing, how should the datum scheme be defined to ensure stable and accurate referencing of the critical holes and functional surfaces?
- Is defining a datum based on a symmetry axis appropriate in this case? What risks does this pose for manufacturing and inspection?
- Does the application of tolerances and GD&T in this drawing follow sound design logic and standard practices? Are there dimensions that should be re - referenced or adjusted to improve stability and clarity?
A.3 3D Model and DFM Analysis Questions
These prompts evaluated geometric reasoning, manufacturability awareness, and understanding of CNC machining constraints.
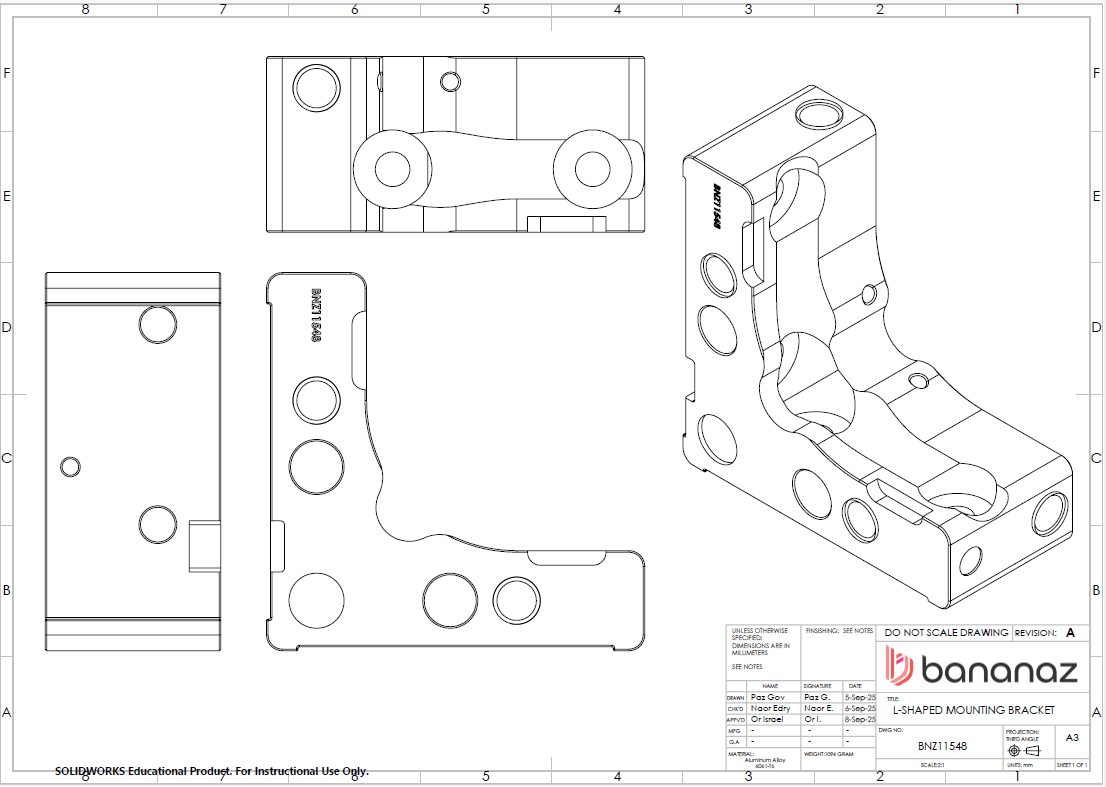
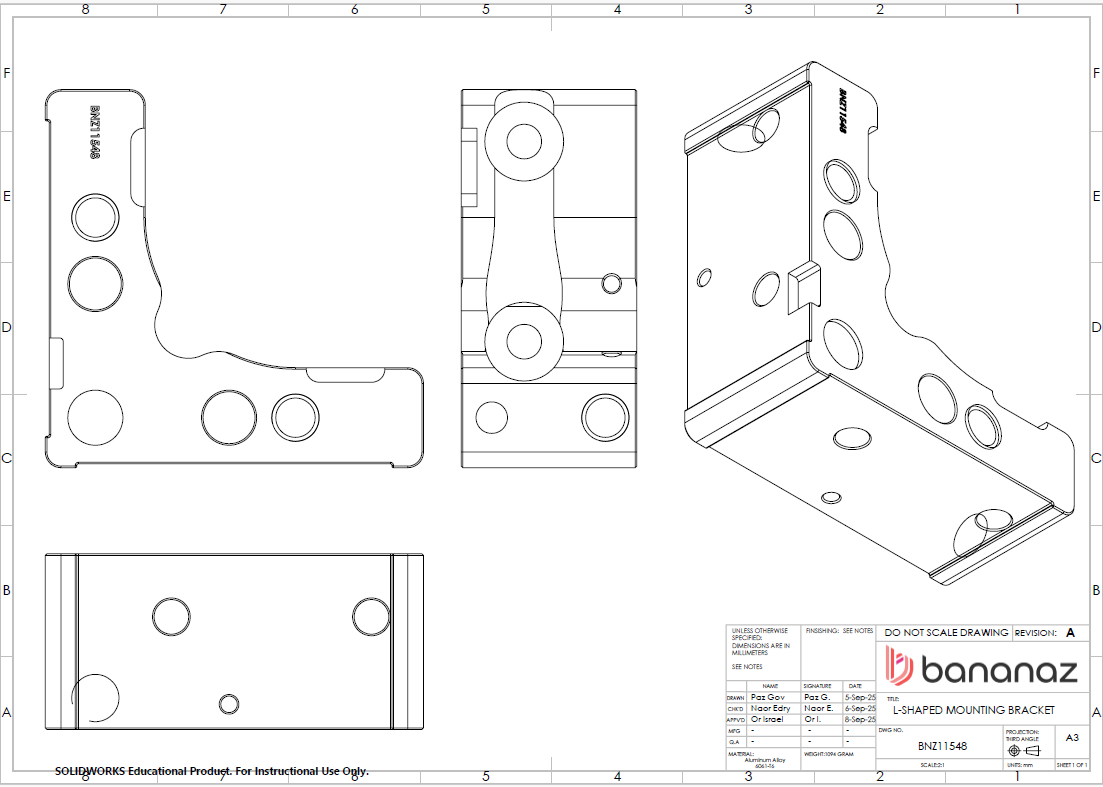
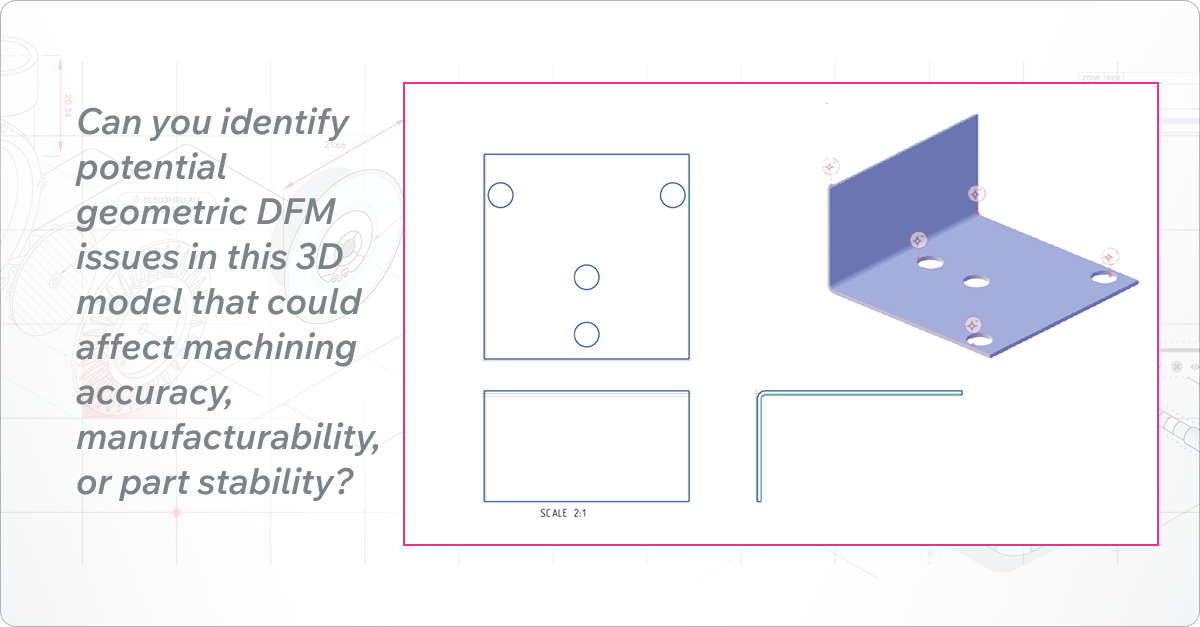
Description:
Machined L-shaped bracket featuring multiple holes, internal corners, and varying wall thicknesses, intended for CNC machining.
- Can you identify potential geometric DFM issues in this 3D model that could affect machining accuracy, manufacturability, or part stability?
- Are there any CNC machining process limitations in this design that may increase cost or complicate tool access?
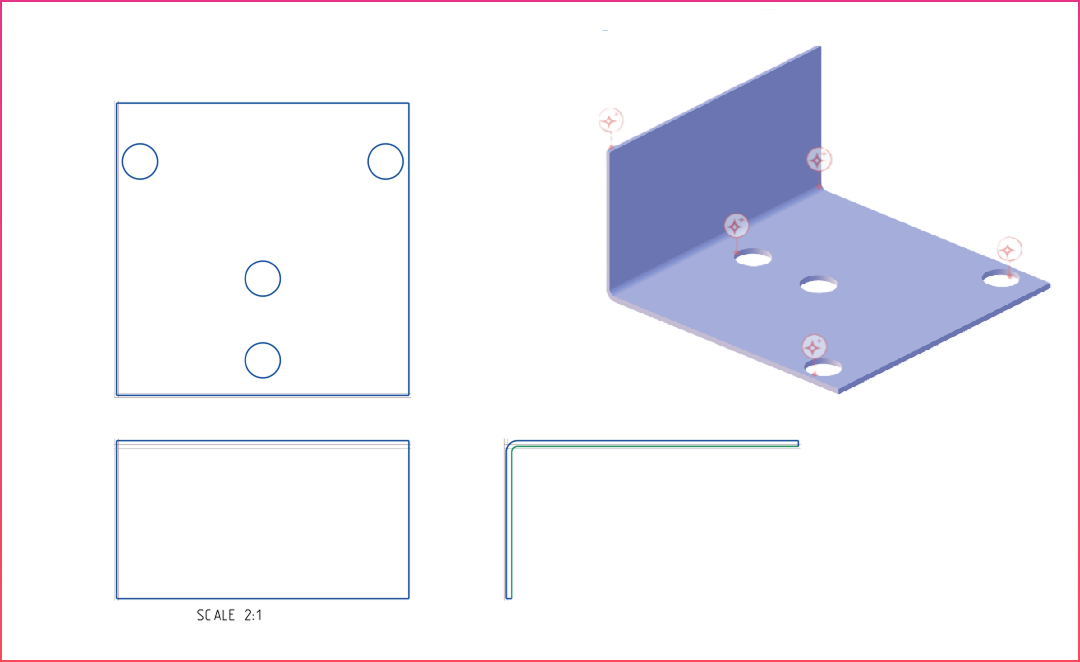
Description:
Sheet-metal bracket formed by bending, including multiple holes located near bends and edges
- Do the hole locations in this model appear properly aligned and spaced according to standard machining and design for manufacturing principles?
- Are the distances between features sufficient for reliable manufacturing, or should certain areas be increased to reduce manufacturing risk?
.png)



